
Building an online datahub with Spark
A guide to building your datahub on or off public clouds.

Organisations demand accurate, timely, high quality data on which to base their
decisions. Building an effective, online data hub to facilitate access to this data
means ensuring solution scalability and reliability. It also means building for data
trustworthiness.
This paper addresses the value, use cases and challenges associated with building
an enterprise data hub – whether on the public cloud or on-premise – based on
Apache Spark.
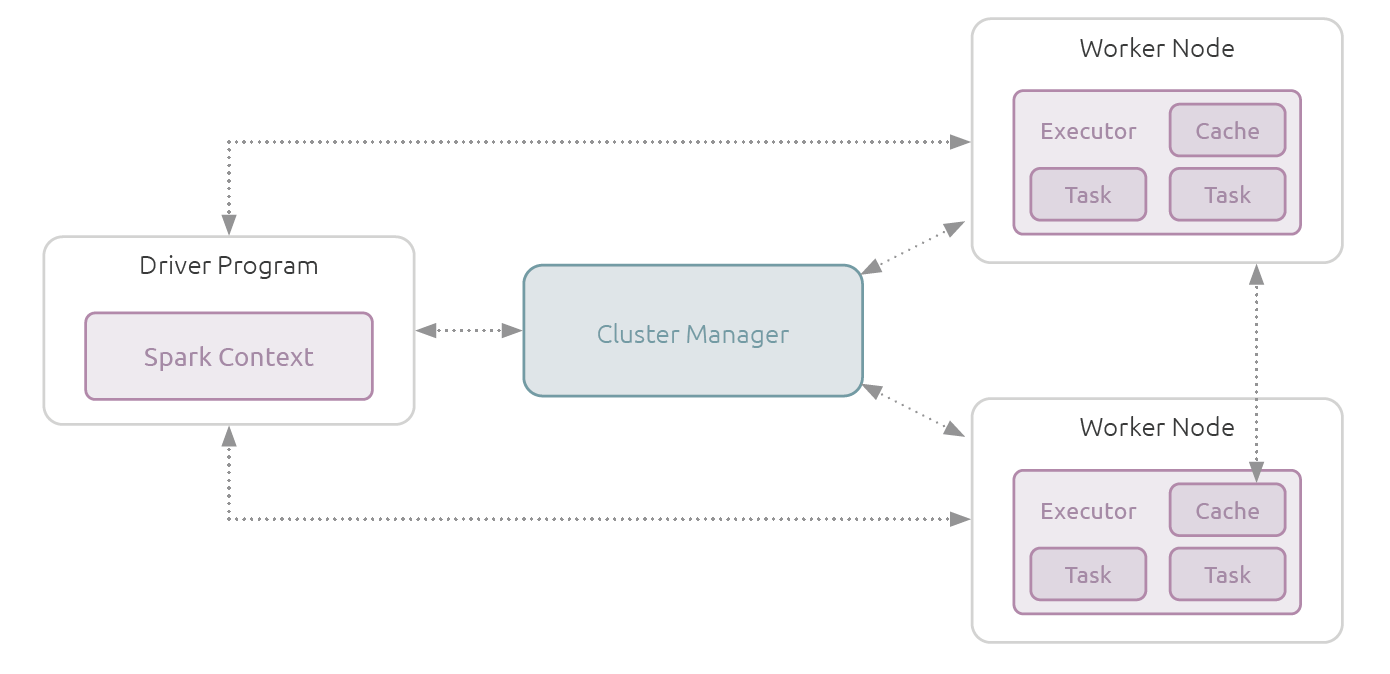
Why Apache Spark for your Datahub
Apache Spark is an open source software development framework and runtime
that helps users develop parallel, distributed data processing and machine
learning applications to run at scale. Spark combines capabilities for in-memory
distributed, grid data processing with the ability to spill intermediary datasets to
disk if required.
In this whitepaper, we cover:
- The value and promise of a data hub
- Common data hub use cases
- Challenges to adoption
- An introduction to Apache Spark
- How Spark helps solve data challenges
- Planning a Spark implementation
- Building a cloud data hub
- Building an on-premise data hub
Further reading: