
Introduction to High Availability
Note:
This documentation has moved to a new home! Please update your bookmarks to the new URL for the up-to-date version of this page.
A definition of High Availability Clusters from Wikipedia:
High Availability Clusters
High-availability clusters (also known as HA clusters , failover clusters or Metroclusters Active/Active ) are groups of computers that support server applications that can be reliably utilised with a minimum amount of down-time.
They operate by using high availability software to harness redundant computers in groups or clusters that provide continued service when system components fail.
Without clustering, if a server running a particular application crashes, the application will be unavailable until the crashed server is fixed. HA clustering remedies this situation by detecting hardware/software faults, and immediately restarting the application on another system without requiring administrative intervention, a process known as failover.
As part of this process, clustering software may configure the node before starting the application on it. For example, appropriate file systems may need to be imported and mounted, network hardware may have to be configured, and some supporting applications may need to be running as well.
HA clusters are often used for critical databases, file sharing on a network, business applications, and customer services such as electronic commerce websites.
High Availability cluster heartbeat
HA cluster implementations attempt to build redundancy into a cluster to eliminate single points of failure, including multiple network connections and data storage which is redundantly connected via storage area networks.
HA clusters usually use a heartbeat private network connection which is used to monitor the health and status of each node in the cluster. One subtle but serious condition all clustering software must be able to handle is split-brain, which occurs when all of the private links go down simultaneously, but the cluster nodes are still running.
If that happens, each node in the cluster may mistakenly decide that every other node has gone down and attempt to start services that other nodes are still running. Having duplicate instances of services may cause data corruption on the shared storage.
High Availability Cluster Quorum
HA clusters often also use quorum witness storage (local or cloud) to avoid this scenario. A witness device cannot be shared between two halves of a split cluster, so in the event that all cluster members cannot communicate with each other (e.g., failed heartbeat), if a member cannot access the witness, it cannot become active.
Example
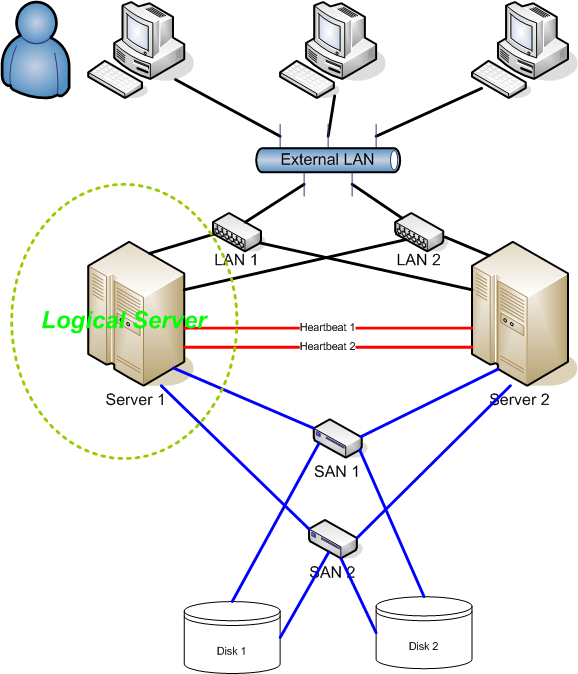
Fencing
Fencing protects your data from being corrupted, and your application from becoming unavailable, due to unintended concurrent access by rogue nodes.
Just because a node is unresponsive doesn’t mean it has stopped accessing your data. The only way to be 100% sure that your data is safe, is to use fencing to ensure that the node is truly offline before allowing the data to be accessed from another node.
Fencing also has a role to play in the event that a clustered service cannot be stopped. In this case, the cluster uses fencing to force the whole node offline, thereby making it safe to start the service
elsewhere. The most popular example of fencing is cutting a host’s power.
Key Benefits:
-
Active counter-measure taken by a functioning host to isolate a misbehaving (usually dead) host from shared data.
-
MOST CRITICAL part of a cluster utilising SAN or other shared storage technology (Ubuntu HA Clusters can only be supported if the fencing mechanism is configured).
-
Required by OCFS2, GFS2, cLVMd (before Ubuntu 20.04), lvmlockd (from 20.04 and beyond).
Linux High Availability Projects
There are many upstream high availability related projects that are included in Ubuntu Linux. This section will describe the most important ones.
The following packages are present in latest Ubuntu LTS release:
Ubuntu HA Core Packages
Packages in this list are supported just like any other package available in [main] repository would be.
| Package | URL |
|---|---|
libqb |
Ubuntu | Upstream |
kronosnet |
Ubuntu | Upstream |
corosync |
Ubuntu | Upstream |
pacemaker |
Ubuntu | Upstream |
resource-agents |
Ubuntu | Upstream |
fence-agents |
Ubuntu | Upstream |
crmsh |
Ubuntu | Upstream |
pcs* |
Ubuntu | Upstream |
cluster-glue |
Ubuntu | Upstream |
drbd-utils |
Ubuntu | Upstream |
dlm |
Ubuntu | Upstream |
gfs2-utils |
Ubuntu | Upstream |
keepalived |
Ubuntu | Upstream |
-
libqb- Library which provides a set of high performance client-server reusable features. It offers high performance logging, tracing, IPC and poll. Its initial features were spun off theCorosynccluster communication suite to make them accessible for other projects. -
Kronosnet-Kronosnet, often referred to asknet, is a network abstraction layer designed for High Availability.CorosyncusesKronosnetto provide multiple networks for its interconnect (replacing the old Totem Redundant Ring Protocol) and add support for some more features like interconnect network hot-plug. -
Corosync- or Cluster Membership Layer, provides reliable messaging, membership and quorum information about the cluster. Currently, Pacemaker supportsCorosyncas this layer. -
Pacemaker - or Cluster Resource Manager, provides the brain that processes and reacts to events that occur in the cluster. Events might be: nodes joining or leaving the cluster, resource events caused by failures, maintenance, or scheduled activities. To achieve the desired availability, Pacemaker may start and stop resources and fence nodes.
-
Resource Agents - Scripts or operating system components that start, stop or monitor resources, given a set of resource parameters. These provide a uniform interface between pacemaker and the managed services.
-
Fence Agents - Scripts that execute node fencing actions, given a target and fence device parameters.
-
crmsh - Advanced command-line interface for High-Availability cluster management in GNU/Linux.
-
pcs - Pacemaker command line interface and GUI. It permits users to easily view, modify and create pacemaker based clusters.
pcsalso providespcsd, which operates as a GUI and remote server forpcs. Togetherpcsandpcsdform the recommended configuration tool for use with pacemaker. NOTE: It was added to the [main] repository in Ubuntu Lunar Lobster (23.10). -
cluster-glue - Reusable cluster components for Linux HA. This package contains node fencing plugins, an error reporting utility, and other reusable cluster components from the Linux HA project.
-
DRBD - Distributed Replicated Block Device, DRBD is a distributed replicated storage system for the Linuxplatform. It is implemented as a kernel driver, several userspace management applications, and some shell scripts. DRBD is traditionally used in high availability (HA) clusters.
-
DLM - A distributed lock manager (DLM) runs in every machine in a cluster, with an identical copy of a cluster-wide lock database. In this way DLM provides software applications which are distributed across a cluster on multiple machines with a means to synchronize their accesses to shared resources.
-
gfs2-utils - Global File System 2 - filesystem tools. The Global File System allows a cluster of machines to concurrently access shared storage hardware like SANs or iSCSI and network block devices.
-
Keepalived - Keepalived provides simple and robust facilities for loadbalancing and high-availability to Linux system and Linux based infrastructures. Loadbalancing framework relies on well-known and widely used Linux Virtual Server (IPVS) kernel module providing Layer4 loadbalancing. Keepalived implements a set of checkers to dynamically and adaptively maintain and manage loadbalanced server pool according their health. On the other hand high-availability is achieved by VRRP protocol.
Ubuntu HA Community Packages
Packages in this list are supported just like any other package available in [universe] repository would be.
| Package | URL |
|---|---|
| pcs* | Ubuntu | Upstream |
| csync2 | Ubuntu | Upstream |
| corosync-qdevice | Ubuntu | Upstream |
| fence-virt | Ubuntu | Upstream |
| sbd | Ubuntu | Upstream |
| booth | Ubuntu | Upstream |
-
Corosync-Qdevice - Its primary use is for even-node clusters, operates at corosync (quorum) layer. Corosync-Qdevice is an independent arbiter for solving split-brain situations. (qdevice-net supports multiple algorithms).
-
SBD - A Fencing Block Device can be particularly useful in environments where traditional fencing mechanisms are not possible. SBD integrates with Pacemaker, a watchdog device and shared storage to arrange for nodes to reliably self-terminate when fencing is required.
Note: pcs was added to the [main] repository in Ubuntu Lunar Lobster (23.04).
Ubuntu HA Deprecated Packages
Packages in this list are only supported by the upstream community . All bugs opened against these agents will be forwarded to upstream IF makes sense (affected version is close to upstream).
Ubuntu HA Related Packages
Packages in this list aren’t necessarily HA related packages, but they have a very important role in High Availability Clusters and are supported like any other package provide by the [main] repository.
| Package | URL |
|---|---|
| multipath-tools | Ubuntu | Upstream |
| open-iscsi | Ubuntu | Upstream |
| sg3-utils | Ubuntu | Upstream |
| tgt OR targetcli-fb* | Ubuntu | Upstream |
| lvm2 | Ubuntu | Upstream |
- LVM2 in a Shared-Storage Cluster Scenario:
CLVM - supported before Ubuntu 20.04
A distributed lock manager (DLM) is used to broker concurrent LVM metadata accesses. Whenever a cluster node needs to modify the LVM metadata, it must secure permission from its localclvmd, which is in constant contact with otherclvmddaemons in the cluster and can communicate a desire to get a lock on a particular set of objects.
lvmlockd - supported after Ubuntu 20.04
As of 2017, a stable LVM component that is designed to replaceclvmdby making the locking of LVM objects transparent to the rest of LVM, without relying on a distributed lock manager.
The lvmlockd benefits over clvm are:
- lvmlockd supports two cluster locking plugins: DLM and SANLOCK. SANLOCK plugin can supports up to ~2000 nodes that benefits LVM usage in big virtualization / storage cluster, while DLM plugin fits HA cluster.
- lvmlockd has better design than clvmd. clvmd is command-line level based locking system, which means the whole LVM software will get hang if any LVM command gets dead-locking issue.
- lvmlockd can work with lvmetad.
Note:
targetcli-fb (Linux LIO)will likely replacetgtin future Ubuntu versions.
Upstream Documentation
The server guide does not have the intent to document every existing option for all the HA related software described in this page, but to document recommended scenarios for Ubuntu HA Clusters. You will find more complete documentation upstream at:
- ClusterLabs
- Other
A very special thanks, and all the credits, to ClusterLabs Project for all that detailed documentation.